
Coding 7: Libraries/Modules/Packages
Finishing off the last of the basic coding series. We will use pip from Python to download and use pandas, and numpy, and using RStudio to download, and install data.tables, and h2o CRAN libraries.

This one will be a doozy, I highly suggest you re-read this a few times.
Quick Recap
Welcome back, as of right now, you have a basic fundamental understanding of how both Python, and R work. You also have a bit of a snippet as to what type of data certain data scientists work with on the regular. This will be the last post on the basics of R, and Python, and this will finish off by allowing you to specialize in whatever direction you wish.
Data Scientists interested in working with Natural Language Processing (NLP) data will be interested in libraries that let you manipulate text data. Those interested in working with neural networks, and artificial intelligence will be interested in libraries that allow you to work with deep learning. Those interested in working alongside data engineers, and software engineers will be interested in libraries that let you code directly in C++, or Java. Lastly, those interested in working with satellite data will be interested in libraries such as ArcPy.
Table of Contents:
What are libraries
How do you download libraries
How do you use them?
Finishing Remarks
1 - What are libraries
When coding, sometimes you will create a file that has a bunch of different custom functions that you spent a lot of time making, wouldn’t it be great to be able to use those custom functions you made on different projects? Luckily, coding lets us do that, the file which has all of the functions we need are called: modules/packages/libraries. All of them basically mean the same thing, the words are very interchangeable.
Python
In Python, if we wish to connect to one of the libraries that we stored locally, we will have to use the import function, and then point to where the library is located. When we install Python to our computer, it comes with a bunch of pre-install libraries ready to go, all we have to do is tell Python to import them. This link has all of the libraries that are ready to go from the get go.
Here is a visual of me importing the random library
We can use the as keyword as an alias. Typing the word random over and over again gets hard, so we use the as keyword to turn random into rd as a shortcut
R

If we want to tell R to run all of the script that exists in another R file, we will use the source() function. If we want R to just pull out all the functions that exist in the other R file, we will use the library(), or the require() function. Here is a link that showcases some more of the differences for your convenience.
2 - How do you download libraries
The Python libraries are commonly hosted on GitHub, and R libraries are hosted on the Comprehensive R Archive Network (CRAN)
Python (Pycharm - PIP)

Here are the steps:
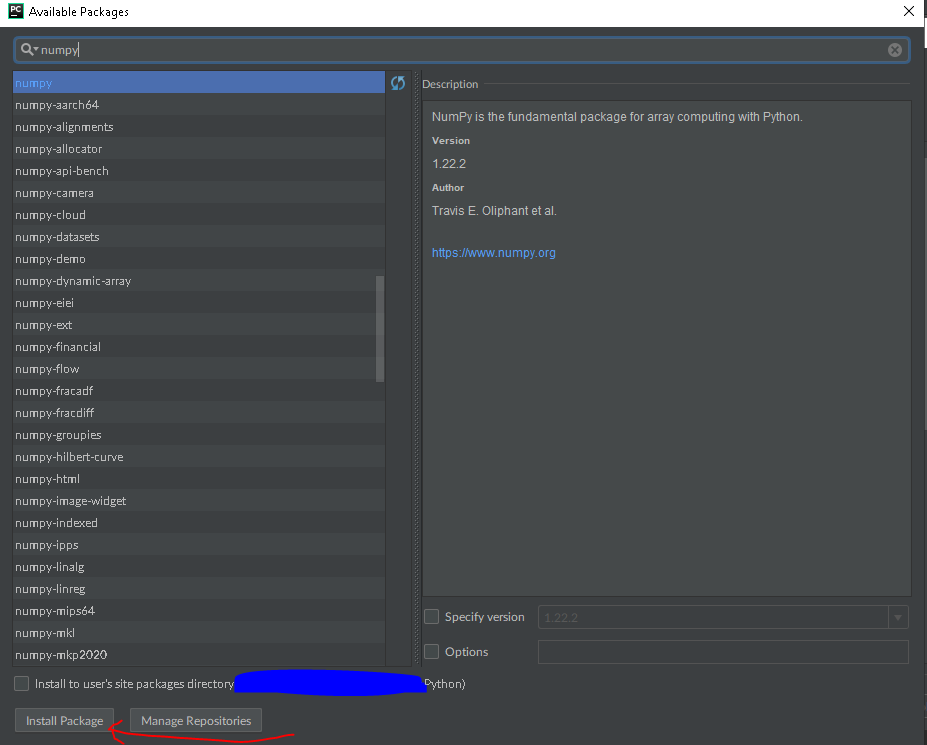
File → Settings → Project → Project Interpreter
Click on the green + on the right, then type in whichever library you wish to install
Click on install package, and Pycharm will get PIP to install it for you, if it’s on GitHub.
Here’s the visualization:
Step 1
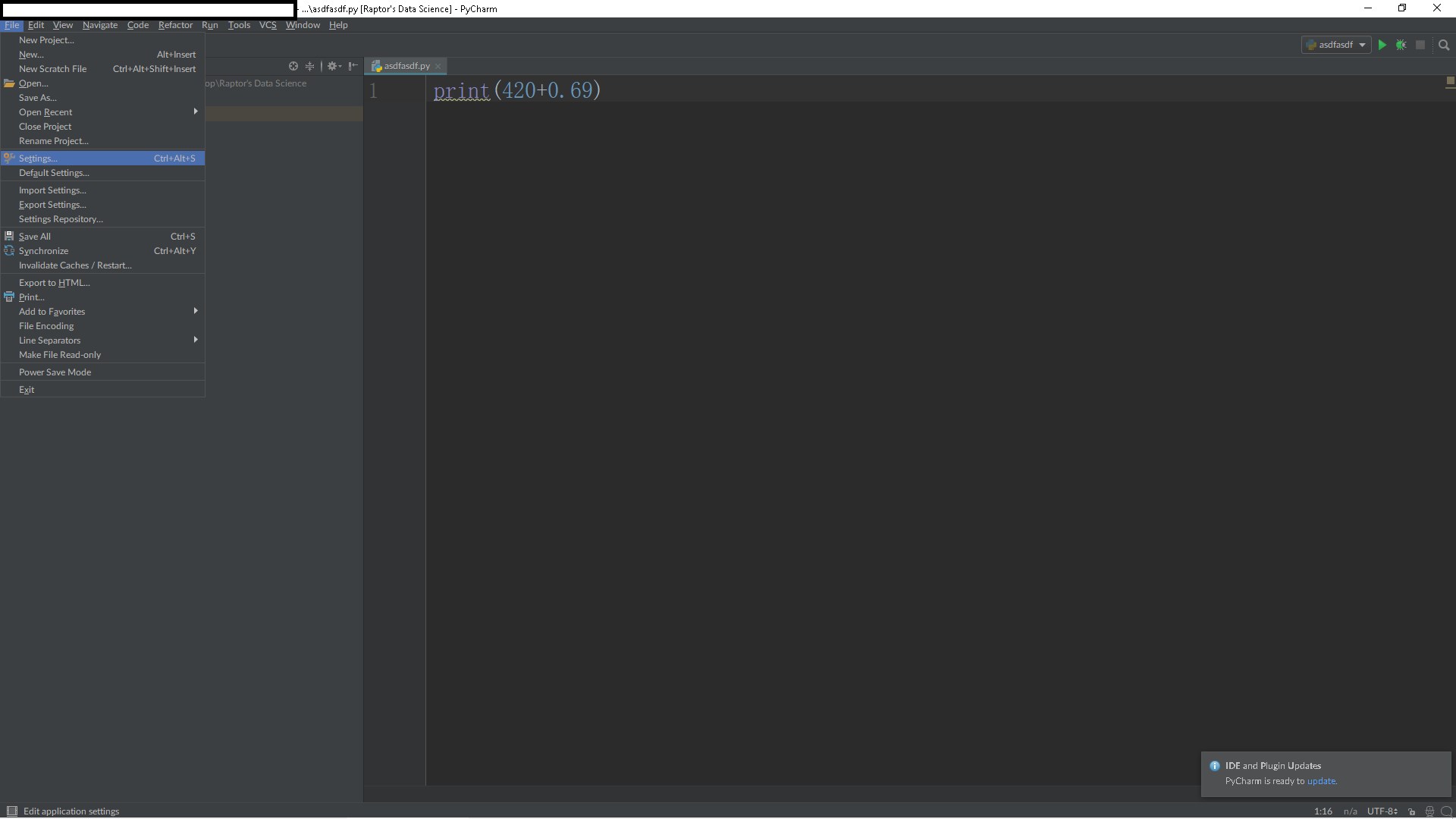
Step 2:

Step 3:
R (RStudio - CRAN)

Here are the steps:
Open up RStudio, and on the bottom right click on packages
Then click on install, and type in the package/library you wish to install from the official CRAN website
make sure the install dependencies is ticked on, and click on install. This will also install the pre-requisites for your library.
Here’s the visualization:
Step 1:
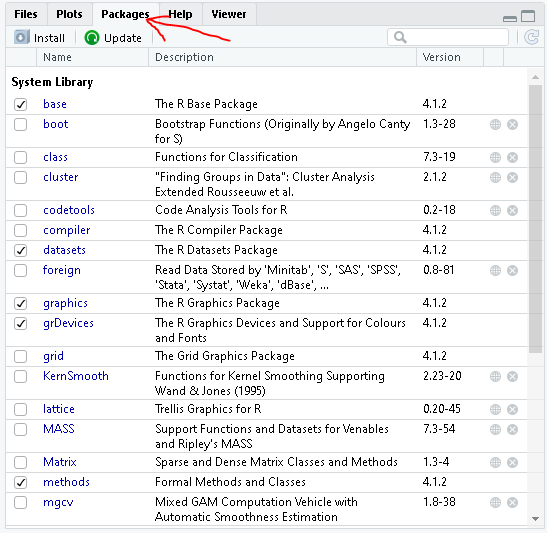
Steps 2 & 3:

3 - How do you use them?
Once we have the libraries we are interested in downloaded, in Python, we use the import() function, and in R, we can use either the require() or the library() function as described above.
Which Libraries should we care about?
Python

pandas: pandas is the most common library that Data Scientists use. Python doesn’t have a way to interact with data tables, thus the pandas library was created. When using the data tables with pandas, we are working with a new type of data called data.frames. As usual, new types of data have their own inbuilt functions that can be used. For pandas, this link shows you the functions we have access to.
numpy: when we are working on heavy linear algebra data (think projections, eigen decompositions, matrix transformations, etc…) we will want to use the numpy library. The numpy library gives us access to a new type of data called an array. An array at the end of the day is just a list inside a list. That part isn’t important, what is important however is that instead of building a bunch of functions for matrix calculations by hand, the numpy library already has a lot of functions we would be interested in, ready to go. For those that are interested in deep learning, and neural networks, you will be using this library on a daily basis. This link gives you a quick tutorial, and shows you the functions we have access to.
scipy: Scipy basically took a lot of the basic functions we used, and recreated them using C, Fortran, and C++. This matters because those who are interested in working right alongside software engineers and web devs, and cloud computing have to care a lot about how well their scripts run. Also, the people who work on deep learning, and big data really have to care about how fast their scripts run, as it’s the difference between waiting 8 hours for the model to finish training, and 4 months. Lastly, this library has access to a lot of the algorithms we would be interested in our Linear Algebra section, so we will definetly end up using it. This link shows you a lot of the linear algebra functions we will have access to.
sklearn: This library has access to a lot of the machine learning, and statistical analysis methods. Just like pandas, this is going to be our bread and butter once we get to the model building section. This link shows you which ML models sklearn has inbuilt.
tensorflow (tensorflow-gpu) & Keras: The tensorflow, and keras libraries are the bread and butter for building deep complex neural networks. Keras is the front end, which makes things look all pretty, whereas tensorflow is the backend which does a lot of the grunt work and calculations. Since GPUs can do more calculations than CPUs, we generally like to work with neural nets on GPUs, however setting up tensorflow-gpu on windows is a giant headache, but much simpler on other Operating Systems.
matplotlib: For all of our visualization, and graphing needs we have the matplotlib library. A quick overview of how many different types of charts we have access to can be seen here, alongside the code.
flask: Flask lets us create simple web applications, and dashboards in Python. This is great because it’s basically like Microsoft’s Tableau, or PowerBI. Basically, if your company expects you to use Python a lot, expect to use this to create a flask app, and then some sort of a server to host the said app.
blpapi: For my dudes/dudettes on WallStreet, the blpapi lets you integrate the data from your bloomberg terminal with your Python Scripts. Meaning, instead of downloading the bloomberg data by hand, you can just use the blpapi library in your script, and basically automate the data feed process. This link contains some of the functions you would be interested in.
R

data.table: Although R has an inbuilt data type called data.frame, the problem with it is that it is extremely slow as R was initially built for mathematical calculations, and not so much for performance. So, to amend this, someone created a new library for R called data.table. Since, in the real world, you will be expected to use data.table as much as possible, we will use data.table instead of data.frame for most of our work. A quick overview of it is available here.
h2o: h2o is basically R’s version of sklearn. This, alongside the data.table library will be your bread and butter for running, and testing machine learning models in R. Here’s link that shows you what models you have access to.
Shiny: This is R’s version of the flask library. We use it to create and host shiny apps that basically serve as a replacement of dashboards such as PowerBI, and Tableau.
stringi: This library offers a lot of tools for manipulating text string data. Incase you forgot, it’s basically an extremely indepth tool for analyzing strings, similar to one of our earlier coding posts. For those that will be interested in working on Natural Language Processing work (NLP), and Quants which are going to be working on Sentiment analysis, you will use this library quite a bit. Here is the reference manual for it.
blpapi: blpapi is the same as the above Python library. However, for those that are using R instead of Python, you have a different link for the documentation of your functions. This link contains some of the functions you would be interested in.
There are a lot more libraries, but I wanted to just in length for some of the above just to give you an idea on how many different directions you could specialize in.
4 - Finishing Remarks
If you weren’t able to understand a lot of the libraries above, don’t worry about it, the next few sections after the basic coding one will have us working in depth with those libraries, and we’ll do enough Kaggle competitions to fully get the hang of how to use them as well.