
Python Data Skills 4: Fetching HTML Table Data
Fetching Tabular data from a webpage, and discussing all of the problems (and their solutions) on how to handle this.

No reason for a long introduction. We’re continuing on the previous post where we used web API to get some data. In this case, we are now fetching some data directly from an HTML page.
Table of Contents:
The Code
HTML Parsing Error
Robot Checks
Changed Tabular Structure
Encoding Errors
1 - The Code
I created some sample code to save you time. You can alter the code and it will let you fetch some tabular data from a webpage. It will then convert it to a pandas Dataframe.
Here are the assumptions made for this code:
Web URL: www.my_api.com/abcd
Column Headers: “col1”, “col2”, “col3”
Table located: The table is after the paragraph tag, and is after the text that says “you can see the table below”
import requests
from bs4 import BeautifulSoup
import pandas as pd
import json
def scrape_data(url, header_text, column_headers):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Find the target table. It's right after the <p> tag.
target_p = soup.find('p', text=header_text)
table = target_p.find_next_sibling('table')
data = []
# Find all rows in the table body and loop through them
for row in table.find('tbody').find_all('tr'):
cols = row.find_all('td')
cols = [col.text.strip() for col in cols]
data.append(dict(zip(column_headers, cols)))
df = pd.DataFrame(data)
return df
url = "http://www.my_api.com/abcd" #swap this to your url
header_text = "you can see the table below" #swap this to your text
column_headers = ["col1", "col2", "col3"] #swap this to your headers
df = scrape_data(url, header_text, column_headers)
print(df)As usual, nothing in life is ever as simple as this.
So, let’s talk about the list of things that can go wrong, and how to solve them.
2 - HTML Parsing Error
2.1 Finding the target <p> tag
The BeautifulSoup library may not be able to find the expected tags. This will happen if the structure of your website is not as the above code expects.
Here is an example:
Let’s look for a specific paragraph (<p> tag). This will be containing the text "you can see the table below". If the structure of the webpage changes so the text is now inside a 'div' tag. BeautifulSoup's find('p', text=header_ text) won't be able to locate the correct tag. This can also happen if another HTML element, or the text itself changes.
As a result, the variable target_p would be None.

This would then result in an an Error. To solve this, you’ll have to re-open the web page via inspect element, and re-configure the script.

2.2 Locating The Table & Rows
After locating the target paragraph, the script expects a 'table' tag to be the next item. If there's no such 'table' tag in the actual HTML, you’ll get a None type in Python. This will then result in an error, when the script tries to locate the rows within the table body.
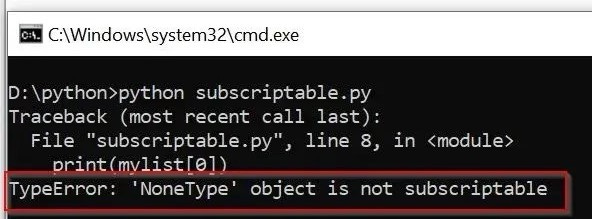
No easy fix for this, you’ll have to investigate the page/website and see what happened. The most likely scenario is that the table got moved to a different web page.
3 - Robot Checks
3.1 Robot Checks
Many websites have measures to prevent or restrict automated data scraping. For instance, some sites use CAPTCHAs. In case you forgot, captcha’s are those annoying things you have to deal with, when you try to login sometimes.

Unfortunately, you can't fix this with basic requests in Python. Websites may also limit the number of requests from a single IP address within a certain period. This is to prevent bots from accessing too much data. If your script stops working or fails to retrieve data, it might be due to hitting such limitations. In these cases, you may need to reduce the frequency of your requests.
The most common way that people handle these issues is by using Selenium. Selenium is an open-source tool that automates web browsers. It supports Python and can you can use it for various tasks on dynamic websites. Examples are filling out forms, clicking buttons, or navigating between pages.
The Selenium method also works pretty well for handling Anti-Scraping Measures.
3.2 Anti-Scraping Measures
Many modern websites use JavaScript to load data. This means that the data is not present when the page is first loaded. If this happens it also fetches and adds it to the page after the fact. For example, a loading spinner is often displayed on websites to show that data is being fetched. It will then populates a table on the page once the data once retrieved. When you use requests.get(), it only fetches the initial HTML of the page. It doesn't execute any JavaScript, so any data loaded in this way will be missing from the retrieved HTML.
You can watch the video below to get an idea of how Selenium can be used to address the waiting component.
4 - Changed Tabular Structure
Web pages are dynamic and can evolve over time, leading to changes in the HTML structure. When we setup an automated process for scraping web data, we assume that the table structure is consistent, and doesn’t change.
Now, let's say the owners add a new column "col4" or remove "col2" from the table, or they could change the orders. Such changes will result in errors or incorrect data during the scraping process. This is because the script continues to look for "col1", "col2", "col3" in the same order. The error could manifest as a ValueError when trying to create a dictionary or DataFrame.
To handle this problem, just take a quick glimpse at the new tabular structure, or feel free to add in some try/except conditions.

5 - Encoding Errors
5.1 - Encoding Mismatch
Sometimes a web page will use different character sets when encoding web pages. The most common one today is UTF-8. It includes all standard characters in the English alphabet. It also includes numbers, and many special characters. Websites across various regions or languages might use distinct character encodings.

For example, a website from Russia might use Cyrillic (ISO-8859-5) encoding. A Chinese website might use GB2312 encoding. A Python script may encounter characters that are not included in the UTF-8 character set. This can happen when parsing a website using the default UTF-8 encoding. In such cases, the presence of unsupported characters during parsing can occur.
5.2 - Decoding Error
UnicodeDecodeError is when Python encounters a character that it can't decode. We will get this error when trying to decode something that is not in the default (UTF-8) encoding. To solve this problem, just find the correct character encoding of the website.

this article is gold. ran into a lot of issues trying to scrape internal webpages to get visitor/usage stats to clean up access. spent several days figuring out "inspect element" and finally using Selenium to do the dirty work! this would have saved me a lot of time