
Data Wrangling 1: Basic Subsets, and Some Performance Tips
We'll use some SQL queries to manipulate some data, then do the exact same thing in Python (pandas) & R (data.table). We will be using the titanic passenger dataset for this series.

Introduction
One of the things that you will have to do a lot is to grab some data, and then tweak said data into whatever forms you need for your job. Nowadays, some (not all) positions want you to take a table, and either tweak it using SQL, or they give you a csv, and expect you to tweak the table to get some conclusions.
This series will be a little bit of a mix of teaching SQL, and how to achieve certain goals using R (data.table) & Python (pandas).
Table of Contents:
Why Should You Care?
5 Steps to Data Wrangling
Downloading Some Data
SQL
Python (pandas)
R (data.table)
Some Obvious Conclusions
1 - Why Should You Care?

Data wrangling means to take the raw data that you have, and tweak it into another more usable form. This could be something as simple as dropping useless columns that we don’t need, all the way up to running some extremely complex SQL queries (I highly suggest you click this for interview prep) & parsing data into specified data structures for storage.
This is important for those in the field because believe it or not, you actually spend about 80% of your time either wrangling, or cleaning up the data, and the remainder 20% of your time doing the actual model building and analysis. You could be doing this such as prepping the data for visualization, prepping it for model building, or doing some super quick summaries (correlation, mean, median, etc…) for the higher ups.
2 - 5 Steps to Data Wrangling
1 Data Discovery
In this phase, you are basically just running some super quick visuals on the data. You want to see which columns have what type of data, and what the mean, and skewness are for some of the numeric columns.
2 Structuring
In this phase, you will want to structure the data to make it actually useful. For example, sometimes when you are working with names, not all of them will have the same formatting. Or sometimes when you are working with year (as numeric), for some reason, there will be an entry in there as a string??? So, in this phase, you will want to fix all of that
3 Cleaning
In this phase, you will want to clean up the data to get rid of a lot of weird headaches in there. This would include things like a typo error, for example if you are looking at year data, typically most numbers should be between 1950 to 2022, there is no reason for 19512 to be in there.
4 Enriching
In this phase, we will want to see if we can get some free data online on the internet, and see if we can add it to our data for even better results.
Macro data is available on Federal Reserve Economic Database (FRED)
Mapping data is available on US Census Bureau
5 Validating
In this phase, we are gonna want to do a final double check on the data that we have. It’s basically like re-checking over your test/exam, before you submit it.
3 - Downloading Some Data
I’m going to download, and use the titanic passenger dataset available here.

For the first gloss over, let’s take a look at how many unique men and women we had on the titanic.
4 - SQL
If you wish to learn SQL, a good resource is w3schools.
I am using this link to load up a csv, and then run SQL queries on it. It is good for some practice before you have a SQL interview.
Number of Females
To look at how many females there were, we use COUNT() in order to count the number of rows. We also use the WHERE clause to specify what condition we are interested in, in this case, we only care about the female passengers.

Number of Males
Same thing as above, but now we want to run it for male only passengers.

5 - Python (pandas)
Loading up the data in Python
We can use the read_csv() function from the pandas library in order to load up the data. If you don’t know how to download and install the pandas library, you can look over here. Here is the code, alongside what the data preview looks like in Python.
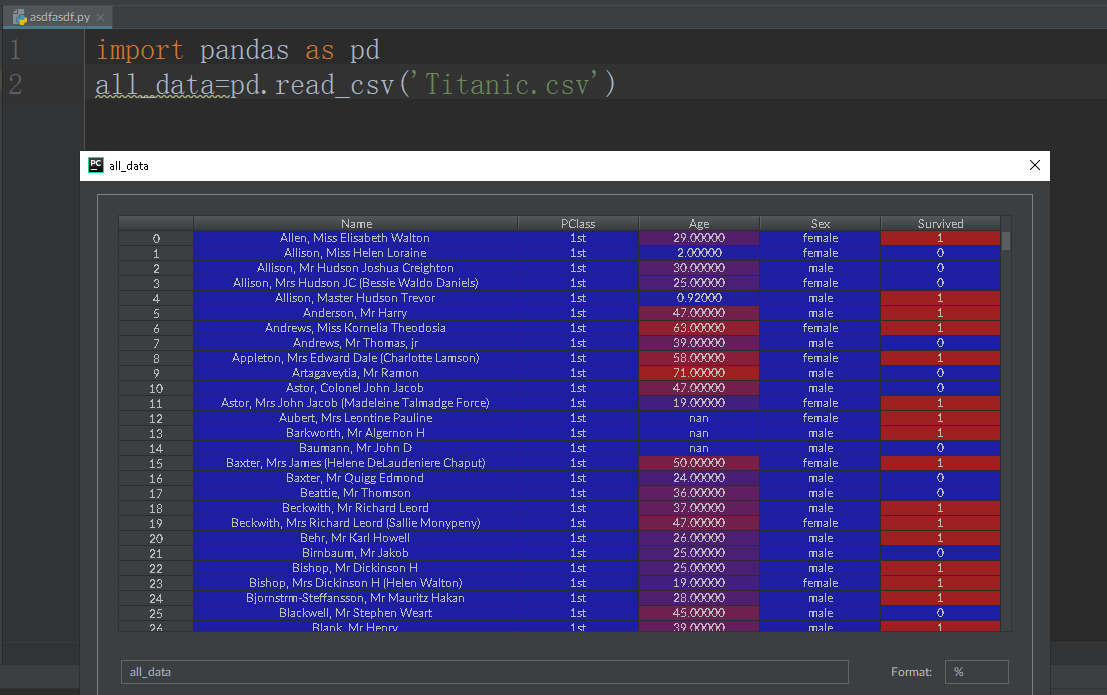
Number of Females
In order to do some sub setting in pandas, we use the .loc method from the pandas library. We will combine this with some basic conditional expressions. Once we’ve successful done the subset, we will want to use the .count method in order to count the number of rows in our new dataframe. Here is what it would look like:

Number of Males
We can apply the exact same methodology, but change the ==’female’ to ‘male’, in order to examine the male data.

6 - R (data.table)
Loading up the data in R
We can use the fread() function from the data.table library. If you don’t know how to download and install the data.tables library, you can look over here. We don’t want to use the default read.csv() function because it is extremely slow. The comparison isn’t even close:

Here is an example of how I used the fread() function in order to load up the data in the csv to a variable called all_data.

Here is the preview of the exact same data above in R:

Number of Females
In order to subset our data to examine only Females, we will have to use some conditional expressions in R, with a mixture of vectorization. Here is what the performance looks like:

Here is an example of using vectorization with a conditional expression in order to subset our data to look at female only passengers on the titanic.
Number of Males
You can use the above code as a template, and just swap out the female for male, and voila, you’ve now subset the titanic passenger dataset to examine only the males on the ship.

7 - Some Obvious Conclusions
A simple observation you can make from using the above data is that there were a lot more male passengers in the Titanic, than females (double). From simple 20/20 hindsight, if there was a 80% death rate among the females, if we assume that the exact same thing applies to the males. Then, we can expect the number of casualties to be: for Females, 370 and 680 for Males, basically, unless Males got special treatment on the ship, we should expect the number of males dead to be much much higher than the number of females on the ship, simply because there were A LOT more of them.
We will do some extremely simple wrangling in the next few posts to confirm, and see if the 80% death rate should be applied to both males and females equally. Or, did something happen, so that generally speaking as a percentage wise, the death rate among the females was a lot less than the males.
Simple conditionals are good to know
Just finish wrangling and creating visualizations for my first data set. I can tell you from stack overflow survey data, python was the most valuable language to know and America was most lucrative place to be a developer.
Really excited to dig into your ML content (I read them as they come out but haven’t worked through them yet).
Thanks raptor.
-BTA