
What *Real* Data Science Looks Like
Why Colleges & BootCamps are actually considered worthless by those who work in the real world.

Reading this post will be like drinking water from a firehose, SLOW DOWN!. Read this post several times over, if you have to.
With the warning post on what kind of scams to watch out for complete. Let’s focus on what Data Science in the real world actually looks like. Lots of college kids continue to spend time learning the modelling aspect. No offense to college kids or their professors, but that’s a bad ROI. We kind of already know what the best models are:
Small Structured Data → Go Lin Reg or Logistic Reg
Huge Structured Data → XGBoost/Gradient Boosted Tree
Clustered Structured Data → KNearest Neighbors
Image Analysis → Convolutional Neural Networks
Need to rank Structured Data → XGBoost with pairwise ranking
If Lazy → Autosklearn
If Have Cash —> Google’s AutoML
Note: If you are applying for a competent data team, this is what you’ll be expected to know. Click here if you want to do some interview prep.
Data Science has been around long enough that most people already know which models to use. Which means model building is the easy part. What will take up around 90% of your time isn’t the modelling, it’s all the other non-fun stuff that you have to deal with. Here’s a pie chart:

Table of Contents:
Idea Generation
Data Gathering
Data Wrangling
Model Building
Presentation
Productionalize
Fun Challenges To Try
1 - Idea Generation (5 hours)
The first step is to come up with an idea on what you’ll be feeding your model. Your idea could come from some research papers you’ve looked at, what your competitors are doing, or what your boss tells you to work on.
You can go to places like arXiv and grab a bunch of research papers on pretty much any topic.

2 - Data Gathering (40 hours)
Welcome to Hell.
Otherwise known as Data Sourcing. This process involves trying to figure out where to get the relevant data to feed your model. This here is why data scientists, and machine learning engineers make serious cash. You’ll see all the different ways to gather data, and how much of a headache each of them can be:
2.1 Easy (CSVs):
CSV (comma-separated values) files are a simple way to store data in a text format. Each line in a csv file represents a record, and each column in a line is separated by commas. This makes it easy to export data from one program into another program. Or to share data between people who are using different software programs. If you try to open them up, you’ll most likely open them up via excel, or notepad. Here’s an example of a csv in a notepad file:

Above is the exact same file I used for the data wrangling 3 post.
Note: For the autists here, yes I know it’s not always a comma, but let’s keep it stupid simple (KISS)
Sometimes, your company won’t have all the data that you need, so you’ll have to go on the internet to find some external data. Here’s a few good sources:
Macro Data → FRED
Canada Statistics → Stats Canada, Climate Weather GC
US Stats → Census.gov, Climate.Gov
Futures Prices → Nasdaq
2.2 Medium (In House Data):
SQL Database
Every company has a SQL database that you’ll connect to. To figure out which table will have the data that you are after, you’ll need to look at what’s called a SQL schema. An example of a SQL schema is below.

A SQL schema will tell you which tables have which entries. And also what the primary keys are that you should use to merge the tables. Once you merged the correct tables together, you can now grab whatever columns you were after.
Sometimes a company can have many SQL databases instead of one. So, you’ll have to coordinate with the data engineer to be pointed in the right direction.
NoSQL Database
Another way companies like to hold onto data is by compressing them a lot. Instead of saving their data as a csv, they sometimes like to save it as a .ndjson file format.
Since this dataset is super super compressed, you won’t be able to load up the entire thing in 1 go. This means you will have to tell Python/R to read the file… row by row.
This means you will have to become good at using if statements, and building super complex for loops. Here’s a good video that explains ndjson, and how you can play with them.
Note: If you are on the younger side, and want to blow your competition away. When you have an interview, give them huge details on data gathering. Talk to them about the libraries you used, the different types of datasets you worked with, any apis used. As much detail as possible. Most of your competition will talk about how good they are at model building, and you will rek them.
2.3 Hard (Turning Garbage Into Tables):
Congrats, you’ll now know why this section is called welcome to hell. Sometimes you’ll have to scrape data from the internet, and make it useful, and then store it into a table. In other words, you will use code that connects to a website. Which then pulls every single blog post, or image, or etc... to a variable.
If we were scraping my own bowtiedraptor’s substack. We would have 1 tuple, and in this tuple, every single piece of word I have written is saved in there as a separate string. Yes, 1 entire blog post is turned into a string…
Your job will then be to come up with some sort of a smart algorithm. This algorithm will use string manipulation to turn tuples into useful data.
We turn this:

Into this:

This shit will drive you nuts. Have fun.
3 - Data Wrangling (10 hours)
Great, awesome, we’ve now got several tables of data ready for our analysis. But, we are not ready yet. We will now have to use all our tools when it comes to data wrangling. We will now do some feature engineering, and do some data cleaning, remove outliers etc..
Over here is where all your knowledge on custom columns comes into play.
4 - Model Building (5 hours)
Now comes the fun easy part. Now that all your data is ready to go, you’ll now funnel all your data into the a few machine learning models. Your goal here to figure out which machine learning model is the best for your current set of data, and the hyper-parameters for it.
If you are lazy like me, you use a for loop, or the autosklearn library, and then go meet up with your tinder date. Here is how easy autosklearn is:
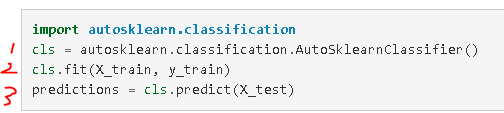
Import the AutoSklearnClassifier
Point it to your training data
Predict with it
And… Just like that, the model building is done.
5 - Presentation (2 hour)
Now it’s time to show your manager what your model tells us. And if it’s worthwhile, prep a presentation with a few charts for the C-Suites.
Over here is where your data visualization skills come into play. For example, if the model picked a few features, the onus is on you to explain why. It will be your responsibility to come up with a few relevant charts to try to explain to the higher ups what’s going on. And, why what the model came up with makes sense.
6 - Productionalize (10 hours)
If the model did great, then you’ll need to put it into production. To achieve this, you'll work with the data engineer to connect your model to a data pipeline. This is to ensure that your model can continue to keep getting a flow of data to predict on, without your input.

You’ll also work with the data engineer to build a data pipeline for the sources of data that you gathered. This will also be another time consuming process.
7 - Fun Challenges To Try
Congratulations, you are done this data science project. Now go back to step 1, and repeat for the next 40 years.
Let’s be real. This career path pays a decent chunk of money, but the work itself is boring. So, with us working from home, let’s make this role a bit interesting.
Here’s a few challenges you can try:
Get your tinder date to go downtown while in a meeting
“Breathing Exercises” - If you know, you know
Use company time to work on your wifi biz
Is the modelling part really that simple with autoscktlearn?
Oh man I have really been wasting my time trying to learn the modelling aspect.
Only upside is that I’ve been focusing on steps 1, 2 and 3.
Would there actually be any value in learning the theoretical components behind each of the modelling techniques you have mentioned though?
I know that one of the data scientists has used some k nearest neighbours clustering analysis based on our datasets.
Captains of crush during meetings another good challenge